

How to Calculate the Cost of Smart Contract?


Dataset
We use KernelBench, a dataset of 250 PyTorch-based classic deep learning tasks. It measures a model’s ability to replace the PyTorch operators with optimized CUDA kernels. We focus on the first two levels, each containing 100 tasks. Level 1 includes foundational tasks such as matrix multiplication, convolution, and loss functions, while level 2 consists of fused operators. We train on 180 tasks of these two levels, with a holdout set of 20 tasks.
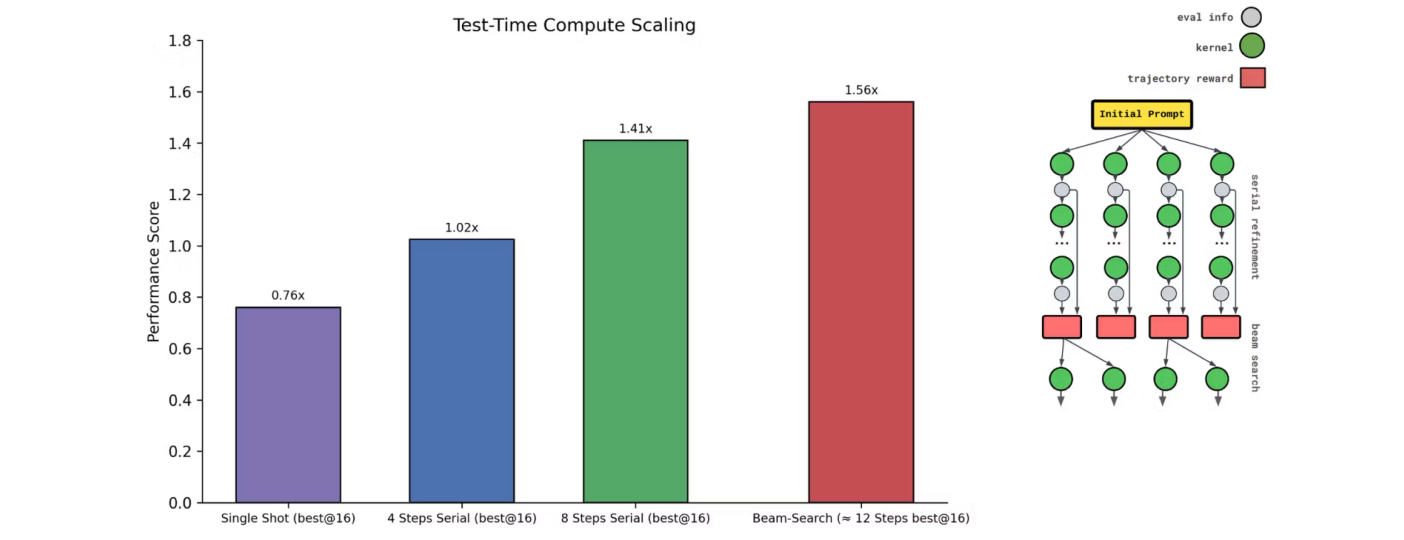
During training, the model goes through an iterative feedback loop: we extract feedback from a generated kernel and have the model refine it. If the kernel fails to compile, we pass the model the error trace and ask it to fix it. If it’s correct, we measure the runtime and ask the model to improve it further.
Our initial approach constructs the trajectories as follows. Starting with the initial prompt, we append the chain of thought, kernel, and evaluation information after each refinement step. We then assign a single reward to the entire trajectory—defined as the maximum score achieved by any kernel—and use this sequence for training.
However, this approach presents several problems:
- Exploding context window: reasoning models generate long chains of thought. With this approach, the length of the trajectory can easily reach 50-100k tokens after just a few passes, becoming prohibitive for training.
- Sample inefficiency and credit assignment: we are assigning a single reward for the entire trajectory even though we generated multiple kernels. This provides no signal on which refinement step actually improved correctness or performance. The rewards should be assigned to refinement steps based on their contribution to the final result.
To fix the exploding context length, we discard the longest part of the trajectory — the chain of thought. Each prompt will now only include the previously generated kernels and evaluation results. To still retain information about the thinking process of the previous step, we ask the model to generate a brief summary of its own thought process, which is then passed to the subsequent contexts.
Tasks
We use KernelBench, a dataset of 250 PyTorch-based classic deep learning tasks. It measures a model’s ability to replace the PyTorch operators with optimized CUDA kernels. We focus on the first two levels, each containing 100 tasks. Level 1 includes foundational tasks such as matrix multiplication, convolution, and loss functions, while level 2 consists of fused operators. We train on 180 tasks of these two levels, with a holdout set of 20 tasks.
Subtask 1
During training, the model goes through an iterative feedback loop: we extract feedback from a generated kernel and have the model refine it. If the kernel fails to compile, we pass the model the error trace and ask it to fix it. If it’s correct, we measure the runtime and ask the model to improve it further.
Our initial approach constructs the trajectories as follows. Starting with the initial prompt, we append the chain of thought, kernel, and evaluation information after each refinement step. We then assign a single reward to the entire trajectory—defined as the maximum score achieved by any kernel—and use this sequence for training.
Subtask 2
However, this approach presents several problems:
- Exploding context window: reasoning models generate long chains of thought. With this approach, the length of the trajectory can easily reach 50-100k tokens after just a few passes, becoming prohibitive for training.
- Sample inefficiency and credit assignment: we are assigning a single reward for the entire trajectory even though we generated multiple kernels. This provides no signal on which refinement step actually improved correctness or performance. The rewards should be assigned to refinement steps based on their contribution to the final result.
To fix the exploding context length, we discard the longest part of the trajectory — the chain of thought. Each prompt will now only include the previously generated kernels and evaluation results. To still retain information about the thinking process of the previous step, we ask the model to generate a brief summary of its own thought process, which is then passed to the subsequent contexts.
KernelBench
We use KernelBench, a dataset of 250 PyTorch-based classic deep learning tasks. It measures a model’s ability to replace the PyTorch operators with optimized CUDA kernels. We focus on the first two levels, each containing 100 tasks. Level 1 includes foundational tasks such as matrix multiplication, convolution, and loss functions, while level 2 consists of fused operators. We train on 180 tasks of these two levels, with a holdout set of 20 tasks.
During training, the model goes through an iterative feedback loop: we extract feedback from a generated kernel and have the model refine it. If the kernel fails to compile, we pass the model the error trace and ask it to fix it. If it’s correct, we measure the runtime and ask the model to improve it further.
Our initial approach constructs the trajectories as follows. Starting with the initial prompt, we append the chain of thought, kernel, and evaluation information after each refinement step. We then assign a single reward to the entire trajectory—defined as the maximum score achieved by any kernel—and use this sequence for training.
However, this approach presents several problems:
- Exploding context window: reasoning models generate long chains of thought. With this approach, the length of the trajectory can easily reach 50-100k tokens after just a few passes, becoming prohibitive for training.
- Sample inefficiency and credit assignment: we are assigning a single reward for the entire trajectory even though we generated multiple kernels. This provides no signal on which refinement step actually improved correctness or performance. The rewards should be assigned to refinement steps based on their contribution to the final result.
To fix the exploding context length, we discard the longest part of the trajectory — the chain of thought. Each prompt will now only include the previously generated kernels and evaluation results. To still retain information about the thinking process of the previous step, we ask the model to generate a brief summary of its own thought process, which is then passed to the subsequent contexts.




